course-web-page-Fall-2021
Repository for the Fall 2021 course web page
View the Project on GitHub IUDataStructuresCourse/course-web-page-Fall-2021
Lecture: Breadth-First Search
Def. a path is a sequence of vertices v(0),…,v(k) such that there is an edge between every vertex and the next one in the sequence (except for the last), i.e., v(i) → v(i+1) ∈ E for i=0… k-1. The length of a path is the number of edges in the path. A path is simple if all the vertices are distinct (no cycles). We sometimes abbreviate a path to v(0) ⇒ v(k) or v(0) ⇒^k v(k) when the length is important. Also, when talking about multiple different paths, we might use a subscript to give the path a name, such as v(0) ⇒ₓ v(k).
Problem: compute the shortest paths from vertex g to all other vertices in the graph.
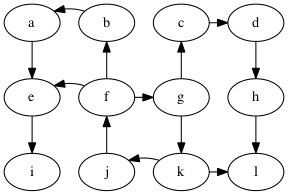
Example: what is a shortest path from g to f?
Possible solution: g → k → j → f, length 3.
To prove this is really the shortest, we need to make sure there are no paths of length less-than 3 from g to f.
How do we prove that? Well, look at all paths of length less-than 3 that start from g.
Length 0 paths:
g
Length 1 paths:
g → c
g → k
Length 2 paths:
g → c → d
g → k → l
g → k → j
Good, none of the paths from g with length less-than 3 reach f.
So indeed, g → k → j → f is the shortest path from g to f.
BFS Algorithm
Towards a general algorithm for BFS, can we compute all the k+1 length shortests paths given all the k-length shortest paths?
Draw a picture of the wave-front of the k-length shortest paths and the out-edges on the wave-front.
High-level Algorithm:
for k = 0...n
for each path s ~>^k u:
for each edge {u,v} incident to u:
If we don't already have a shortest-path to v,
then s ~>^{k+1} u is a shortest path from s to v.
What data structures should we use?
-
The shortest paths form a tree: for each vertex v, store the previous vertex u in its shortest path. we call u the “parent” of v because u is the parent of v in the tree of shortest paths. This is also called the breadth-first tree.
-
For the paths of length k: We just need the end vertex of each path, so let’s maintain a bag of the vertices at the ends of the paths of length k.
-
To make sure we ignore vertices that have already been encountered, we use an array called
donethat maps vertex numbers to True/False.
Version 1 of the algorithm
static <V> void bfs_v1(Graph<V> G, V start, Map<V,Boolean> visited,
Map<V,V> parent) {
for (V v : G.vertices())
visited.put(v, false);
int k = 0;
ArrayList<V> ends = new ArrayList<V>();
ends.add(start);
parent.put(start, start);
visited.put(start, true);
while (k != G.num_vertices()) {
ArrayList<V> new_ends = new ArrayList<V>();
for (V u : ends)
for (V v : G.adjacent(u))
if (! visited.get(v)) {
parent.put(v, u);
new_ends.add(v);
visited.put(v, true);
}
ends = new_ends;
++k;
}
}
Some observations about version 1
-
If the
new_endsis empty at the end of the loop body, then we can stop early. -
The
endsandnew_endscan be combined into a single data structure if we use a queue instead of two bags.The front part of the queue represents
endsand the back part of the queue representsnew_ends.With this change, we can simplify the code by combining the
while kand thefor uloops into a single loop that checks whether the queue is non-empty.
Version 2 of the algorithm
static <V> void bfs(Graph<V> G, V start, Map<V,Boolean> visited,
Map<V,V> parent) {
for (V v : G.vertices())
visited.put(v, false);
Queue<V> Q = new LinkedList<V>();
Q.add(start);
parent.put(start, start);
visited.put(start, true);
while (! Q.isEmpty()) {
V u = Q.remove();
for (V v : G.adjacent(u))
if (! visited.get(v)) {
parent.put(v, u);
Q.add(v);
visited.put(v, true);
}
}
}
Student group work
Example run of BFS version 2
queue parents
[A] P[A] = A
[B,D] P[B] = A, P[D] = A
[D,C] P[C] = B
[C,E] P[E] = D
[E]
[]
Time complexity of BFS
- Main loop: we traverse the entire adjacency list graph once and the combined length of the adjacency lists is O(m), so we have O(m) for the main loop.
- Initialization: O(n) time and space for the parent and done arrays.
- Total: O(n + m)
Lecture: Depth-first Search
This search chooses to go deeper at each step, following an out-edge from the current vertex to a never-before-seen vertex. If there are no out-edges to never-before-seen vertices, then the search backtracks to the last visited vertex with out-edges to never-before-seen vertices and continues from there.
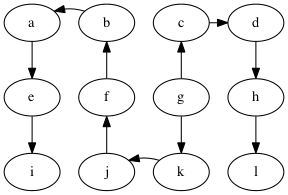
Show DFS on the following graph, starting at g:
Similar to BFS, DFS traverses a tree, a depth-first tree:
For generic search problems, that is, looking for a vertex with a particular property, DFS and BFS both are good choices.
- BFS may require more storage if the graph has many high degree vertices because the queue gets big.
- On the other hand, if the graph contains long paths, then DFS will use a lot of storage for it’s stack.
- If there are infinitely long paths in the graph, then DFS may not be a good choice.
Student group work
Perform DFS on the following graph
Solutions (there are multiple depth-first trees)
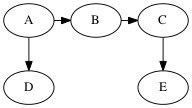
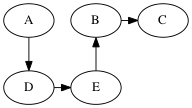
Are any of the DFS trees the same as a BFS tree for this graph? Why not?
Edge Categories
We can categorizes the edges of the graph with respect to the depth-first tree in the following way:
- tree edge: an edge on the tree, e.g., g → c in the graph above.
- back edge: an edge that connects a descendent to an ancestor with respect to the tree, e.g., f → g.
- forward edge: an edge that connects an ancestor to a descendent wrt. the tree, e.g., f → e
- cross edge: all other edges, e.g., k → l.
A graph has a cycle if and only if there is a back edge.
The DFS algorithm can compute the categories if we use a color
scheme to mark the vertices instead of just using a done flag.
The colors are:
- white: the vertex has not been discovered
- gray: the vertex has been discovered but some of its descendents have not yet been discovered
- black: the vertex and all of its descendents have been discovered
During DFS, when considering an out-edge of the current vertex, the edge can be categorized as follows:
- the target vertex is white: this is a tree edge
- the target vertex is gray: this is a back edge
- the target vertex is black: this could either be a forward or cross edge
Do the DFS example again but with the white/gray/black colors.
Discover and Finish Times
We can discover yet more structure of the graph if we record timestamps on a vertex when it is discovered (turned from white to gray) and when it is finished (turned from gray to black).
This is useful when constructing other algorithms that use DFS, such as topological sort. Here are the discover/finish times for the DFS tree we computed above, shown again below.
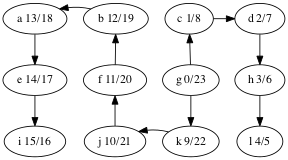
What’s the relationship between topological ordering and depth-first search?
Let’s look at the depth-first forest and discover/finish times of the makefile graph.
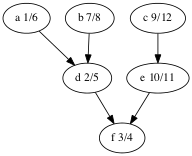
Here’s the vertices ordered by finish time: f,d,a,b,e,c.
That’s the reverse of one of the topological orders: c,e,b,a,d,f.
Why is that? A vertex is finished after every vertex that depends on it is finished. That’s the same as topological ordering except we’ve swapped before for after.